2025-07-16 23:58:54

“All innovation comes from industry is just wrong, universities invented many useful things.”
But that’s not the argument. Nobody thinks that Knuth contributed nothing to software programming.
Rather the point is that the direction of the arrow is almost entirely wrong. It is not
academia → industry → consumers
This is almost entirely wrong. I am not saying that the arrows do not exist… but it is a complex network where academia is mostly on the receiving end. Academia adapts to changes in society. It is rarely the initiator as far as technological innovation goes.
But let me clarify that academia does, sometimes, initiate innovation. It happens. But, more often, innovation actually starts with consumers (not even industry).
Take the mobile revolution. It was consumers who took their iPhone to work and installed an email client on it. And they changed the nature of work, creating all sorts of new businesses around mobile computing.
You can build some kind of story to pretend that the iPhone was invented by a professor… but it wasn’t.
Also, it wasn’t invented by Steve Jobs. Not really. Jobs paid close attention to consumers and what they were doing, and he adapted the iPhone. A virtuous circle arose.
So innovation works more like this…
academia ← industry ← consumers
If we are getting progress in AI right now, it is because consumers are adopting ChatGPT, Claude and Grok. And the way people are using these tools is pushing industry to adapt.
Academia is almost nowhere to be seen. It will come last. In the coming years, you will see new courses about how to build systems based on large language models. This will be everywhere after everyone in industry has adopted it.
And we all know this. You don’t see software engineers going back to campus to learn about how to develop software systems in this new era.
Look, they are still teaching UML on campus. And the only way it might die is that it is getting difficult to find a working copy of Rational Rose.
In any case, the fact that innovation is often driven by consumers explain largely why free market economies like the United States are where innovation comes from. You can have the best universities in the world, and the most subsidized industry you can imagine… without consumers, you won’t innovate.
2025-07-15 23:49:23

« Normal science, the activity in which most scientists inevitably spend most all their time, is predicated on the assumption that the scientific community knows what the world is like. Normal science often suppresses fundamental novelties because they are necessarily subversive of its basic commitments. As a puzzle-solving activity, normal science does not aim at novelties of fact or theory and, when successful, finds none. » Thomas Kuhn
The linear model of innovation is almost entirely backward. This model describes progress like so: University professors and their students develop the new ideas, these ideas are then taken up by industry which deploys them.
You can come up with stories that are supportive of this model… But on the ground, we are still fighting to get UML and the waterfall model off the curriculum. Major universities still forbid the use of LLMs in software courses (as if they could).
Universities are almost constantly behind. Not only are they behind, they often promote old, broken ideas. Schools still teach about the ‘Semantic Web’ in 2025.
Don’t get me wrong. The linear model can work, sometimes. It obviously can. But there are preconditions, and these preconditions are rarely met.
Part of the issue is ‘peer review’ which has grown to cover everything. ‘Peer review’ means ‘do whatever your peers are doing and you will be fine’. It is fundamentally reactionary.
Innovations still emerge from universities, but through people who are rebels. They either survive the pressure of peer review, or are just wired differently.
Regular professors are mostly conservative forces. To be clear, I do not mean ‘right wing’. I mean that they are anchored in old ideas and they resist new ones.
Want to see innovation on campus ? Look for the rebels.
2025-07-15 07:12:29

0One of my most popular blog posts of all times is Data alignment for speed: myth or reality? According to my dashboard, hundreds of people a week still load the old blog post. A few times a year, I get an email from someone who disagrees.
The blog post makes a simple point. Programmers are often told to worry about ‘unaligned loads’ for performance. The point of my blog post is that you should generally no worry about alignment when optimizing your code.
An unaligned load occurs when a processor attempts to read data from memory at an address that is not properly aligned. Most computer architectures require data to be accessed at addresses that are multiples of the data’s size (e.g., 4-byte data should be accessed at addresses divisible by 4). For example, a 4-byte integer of float should be loaded from an address like 0x1000 or 0x1004 (aligned), but if the load is attempted from 0x1001 (not divisible by 4), it is unaligned. In some conditions, an unaligned load can crash your system and it general leads to ‘undefined behaviors’ in C++ or C.
Related to this alignment issue is that data is typically organized in cache lines (64 bytes or 128 bytes or most systems) that are loaded together. If you load data randomly from memory, you might touch two cache lines which could cause an additional cache miss. If you need to load data spanning two cache lines, there might be a penalty (say one cycle) as the processor needs to access the two cache lines and reassemble the data. Further, there is also the concept of a page of memory (4 kB or more). Accessing an additional page could be costly, and you typically want to avoid accessing more pages than you need to. However, you have to be somewhat unlucky to frequently cross two pages with one load operation.
How can you end up with unaligned loads? It often happens when you access low-level data structures, assigning data to some bytes. For example, you might load a binary file from disk, and it might say that all the bytes after the first one are 32-bit integers. Without copying the data, it could be difficult to align the data. You might also be packing data: imagine that you have a pair of values, one that fits in byte and the other that requires 4 bytes. You could pack these values using 5 bytes, instead of 8 bytes.
There are cases were you should worry about alignment. If you are crafting your own memory copy function, you want to be standard compliant (in C/C++) or you need atomic operations (for multithreaded operations). You might also encounter 4K Aliasing, an issue Intel describes where arrays stored in memory at locations that are nearly a multiple of 4KB can mislead the processor into thinking data is being written and then immediately read.
However, my general point is that it is unlikely to be a performance concern.
I decided to run a new test given that I haven’t revisited this problem since 2012. Back then I used a hash function. I use SIMD-based dot products with either ARM NEON intrinsics or AVX2 intrinsics. I build two large arrays of 32-bit floats and I compute the scalar product. That is, I multiply the elements and sum the products. The arrays fit in a megabyte so that we are not RAM limited.
I run benchmarks on an Apple M4 processor as well as on an Intel Ice Lake processor.
On the Apple M4… we can barely see the alignment (10% effect).
| Byte Offset | ns/float | ins/float | instruction/cycle |
|---|---|---|---|
| 0 | 0.059 | 0.89 | 2.93 |
| 1 | 0.064 | 0.89 | 2.75 |
| 2 | 0.062 | 0.89 | 2.82 |
| 3 | 0.064 | 0.89 | 2.69 |
| 4 | 0.062 | 0.89 | 2.84 |
| 5 | 0.064 | 0.89 | 2.75 |
| 6 | 0.062 | 0.89 | 2.69 |
| 7 | 0.064 | 0.89 | 2.75 |
And we cannot see much of an effect on the Intel Ice Lake processor.
| Byte Offset | ns/float | ins/float | instruction/cycle |
|---|---|---|---|
| 0 | 0.086 | 0.38 | 1.36 |
| 1 | 0.087 | 0.38 | 1.36 |
| 2 | 0.087 | 0.38 | 1.36 |
| 3 | 0.087 | 0.38 | 1.36 |
| 4 | 0.086 | 0.38 | 1.36 |
| 5 | 0.087 | 0.38 | 1.36 |
| 6 | 0.086 | 0.38 | 1.36 |
| 7 | 0.086 | 0.38 | 1.36 |
Using the 512-bit registers from AVX-512 does not change the conclusion.
My point is not that you cannot somehow detect the performance difference due to alignment in some tests. My point is that it is simply not something that you should generally worry about as far as performance goes.
2025-07-13 01:19:16
Studying productivity is challenging. About 15-20 years ago, I was obsessed over my own productivity.
I created a spying agent to monitor my activities and time spent. It would look at which window is opened, and so forth. I would also monitor which web sites were loaded, and so forth.
I discovered that I spent over 40% of my day on email, which was shocking. However, this didn’t improve my productivity.
Why is it so hard? The issue is that you’re likely not measuring what you think. Productivity is value per unit of time, but defining “value” is problematic.
Long-term, value follows a Pareto distribution, where most value is created in unpredictable, short bursts.
For instance, a sudden idea in the shower might lead to an hour of work equivalent in value to the rest of the month’s efforts.
Does it mean that you should slack off, wait for the brilliant insight? No. That’s the problem with the Pareto distribution in general.
Maybe you are running a company and figure that 20% of your employees do 80% of the work. So you fire the 80% that are less productive. And what happens? Maybe you find out that Joe, who seemed unproductive, was holding your business together and you need to rehire him quickly.
The fundamental issue is that you have limited knowledge. You do not know where the value lies when you are in the middle of it. So by slacking off, you are likely to just greatly diminish the probability that you will have a sudden burst of high productivity.
Long term, you can probably identify the less productive activities. Maybe you have been going to these meetings for two years now, and nothing got done.
But this like side project of yours, that looks like a waste of time, could be (truly) the most important work you could be doing.
So you should humble and patient. Don’t waste time micromanaging yourself or others. You know less than you think.
2025-07-10 04:33:11
The Apple M2, introduced in 2022, and the Apple M4, launched in 2024, are both ARM-based system-on-chip (SoC) designs featuring unified memory architecture. That is, they use the same memory for both graphics (GPU) and main computations (CPU). The M2 processor relies on LPDDR5 memory whereas the M4 relies on LPDDR5X which should provide slightly more bandwidth.
The exact bandwidth you get from an Apple system depends on your configuration. But I am interested in single-core random access performance. To measure this performance, I construct a large array of indexes. These indexes form a random loop: starting from any element, if you read its value, treat it as an index, move to this index and so forth, you will visit each and every element in the large array. This type of benchmark is often described as ‘pointer chasing’ since it simulates what happens when your software is filled with pointers to data structures which themselves are made of pointers, and so forth.
When loading any value from memory, there is a latency of many cycles. Thankfully, modern processors can sustain many such loads at the same time. How many depends on the processor but modern processors can sustain tens of memory requests at any given time. This phenomenon is part of what we call memory-level parallelism : the ability of the memory subsystem to sustain many tasks at once.
Thus we can split the pointer-chasing benchmark into lanes. Instead of starting at just one place, you can start at two locations at once, one at the ‘beginning’ and the other at the midpoint. And so forth. I refer the number of such divisions as a ‘lane’. So it is one lane, two lanes and so forth. Obviously, the more lanes you have, the faster you can go. From how fast you can go, you can estimate the effective bandwidth by assuming that each hit in the array is equivalent to loading a cache line (128 bytes). The array is made of over 33 million 64-bit words.
I run my benchmarks on two processors (Apple M2 and Apple M4). I have to limit the number of lanes since beyond a certain point, there is too much noise. A maximum of 28 lanes works well.
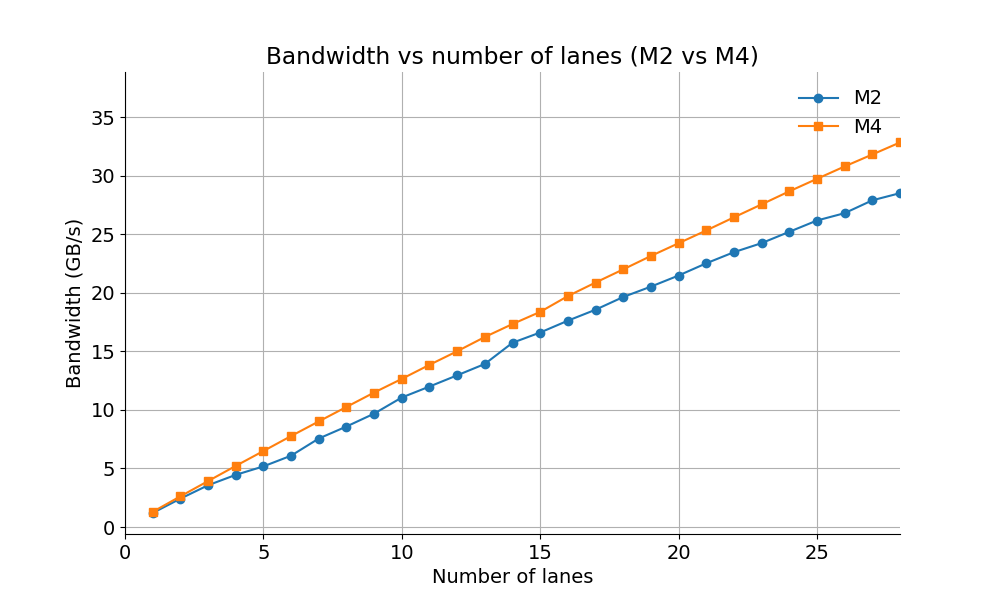
Maybe unsurprisingly, I find that the difference between the M4 and the M2 is not enormous (about 15%). Both processors can visibly sustain 28 lanes.
2025-07-04 21:49:03

JSON, or JavaScript Object Notation, is a lightweight data-interchange format. It is widely used for transmitting data between a server and a web application, due to its simplicity and compatibility with many programming languages.
The JSON format has a simple syntax with a fixed number of data types such as strings, numbers, Booleans, null, objects, and arrays. Strings must not contain unescaped control characters (e.g., no unescaped newlines or tabs); instead, special characters must be escaped with a backslash (e.g., the two characters ‘\n’ replace the newline character). Numbers must follow valid formats, such as integers (e.g., 42), floating-point numbers (e.g., 3.14), or scientific notation (e.g., 1e-10). The format is specified formally in the RFC 8259.
Irrespective of your programming language, there are readily available libraries to parse and generate valid JSON. Unfortunately, people who have not paid attention to the specification often write buggy code that leads to malformed JSON. Let us consider the strings, for example. The specification states the following:
All Unicode characters may be placed within the quotation marks, except for the characters that MUST be escaped: quotation mark, reverse solidus, and the control characters (U+0000 through U+001F).
The rest of the specification explains how characters must be escaped. For example, any linefeed character must be replaced by the two characters ‘\n’.
Simple enough, right? Producing valid JSON is definitively not hard. Programming a function to properly escape the characters in a string can be done by ChatGPT and it only spans four or five lines of code, at most.
Sadly, some people insist on using broken JSON generators. It is a recurring problem as they later expect parsers to accept their ill-formed JSON. By breaking interoperability you lose the core benefit of JSON.
Let me consider a broken JSON document:
{"key": "value\nda"}
My convention is that \n is the one-byte ASCII control character linefeed, unless otherwise stated. This JSON is not valid. What happens when you try to parse it?
Let us try Python:
import json json_string = '{"key": "value\nda"}' data = json.loads(json_string)
This program fails with the following error:
json.decoder.JSONDecodeError: Invalid control character at: line 1 column 15 (char 14)
So the malformed JSON cannot be easily processed by Python.
What about JavaScript?
const jsonString = '{"key": "value\nda"}'; let data = JSON.parse(jsonString);
This fails with
SyntaxError: Bad control character in string literal in JSON at position 14 (line 1 column 15)
What about Java? The closest thing to a default JSON parser in Java is jackson. Let us try.
import com.fasterxml.jackson.databind.ObjectMapper; import java.util.Map; void main() { String jsonString = "{\"key\": \"value\nda\"}"; Map<String, Object> data = parseJson(jsonString); }
I get
JSON parsing error: Illegal unquoted character ((CTRL-CHAR, code 10)): has to be escaped using backslash to be included in string value
What about C#?
using System.Text.Json; string jsonString = "{"key": "value\nda"}"; using JsonDocument doc = JsonDocument.Parse(jsonString);
And you get, once again, an error.
In a very real sense, the malformed JSON document I started with is not JSON. By accommodating buggy systems instead of fixing them, we create workarounds that degrade our ability to work productively.
We have a specific name for this effect: technical debt. Technical debt refers to the accumulation of compromises or suboptimal solutions in software development that prioritize short-term progress but complicate long-term maintenance or evolution of the system. It often arises from choosing quick fixes, such as coding around broken systems instead of fixing them.
To avoid technical debt, systems should simply reject invalid JSON. They pollute our data ecosystem. Producing correct JSON is easy. Bug reports should be filled with people who push broken JSON. It is ok to have bugs, it is not ok to expect the world to accommodate them.